OpenCode Go + Oh My OpenAgent: The Model Routing Config That Actually Saves Money
OpenCode Go limits are dollar-denominated, not request-based. That changes everything about routing. Complete opencode.json + .omc/config.json setup to run 10 agents across 8 models for $10/month.

Most guides on OpenCode Go start with the models. I want to start with the thing most guides get wrong: the limits are denominated in dollars, not requests.
That sounds like a minor distinction. It isn't.
The thing everyone misses
OpenCode Go costs $5 for the first month, then $10/month. Your usage cap is $12 per 5-hour window, $30/week, $60/month.
When you spend $12 in a 5-hour window on DeepSeek V4 Flash, you get approximately 31,650 requests. When you spend the same $12 on GLM-5.1, you get around 880. Same budget. 36x difference in volume.
This is why routing actually matters. If you pick one model and use it for everything, you are either burning premium requests on tasks that don't need them, or you are under-using cheap models that are surprisingly capable. The right move is assigning models to tasks based on what each task actually requires.
MiniMax M2.5 has a hard cap of 100,000 requests per month regardless of cost. That is not a typo. It activates only ~10B parameters and is priced at 16.7x cheaper than Claude Opus 4.6 on input tokens. For high-volume low-complexity work, it is the obvious choice, and most people don't know it exists.
What you lose running on a single premium model
Say you put everything through DeepSeek V4 Pro: 10,200 requests per 5-hour window. That sounds fine for light use. But Oh My OpenAgent runs multiple agents in parallel. Prometheus decomposes your task, Metis synthesizes context, Atlas manages sequencing, Sisyphus runs execution, and the Librarian reads docs. A single complex task can fan out into 30-50 requests without you doing anything. Your 5-hour budget evaporates in a few hours of active work.
The problem isn't the quality gap. V4 Pro at 80.6% is within 7 percentage points of Claude Opus 4.7 at 87.6%, and for most routine tickets that gap is invisible. The problem is you don't need that quality for every step of a multi-agent workflow.
The tier breakdown with actual numbers
Here is what the available models score on benchmarks that matter for coding tasks, plus the API pricing that drives the routing math:
| Model | SWE-Bench Verified | Input price (per M tokens) | Requests/5hrs ($12) | Context |
|---|---|---|---|---|
| Claude Opus 4.7 | 87.6% | $5.00 | ~480 | 200K tokens |
| DeepSeek V4 Pro | 80.6% | $0.435 (promo, ends May 31) | ~5,500 | 1M tokens |
| Kimi K2.6 | 80.2% | $0.95 | ~2,500 | 256K tokens |
| Claude Sonnet 4.6 | 79.6% | $3.00 | ~800 | 200K tokens |
| MiMo-V2.5-Pro | 78.9% | ~$0.40 | ~6,000 | — |
| Qwen3.6 Plus | 78.8% | $0.325 | ~7,400 | 1M tokens |
| DeepSeek V4 Flash | ~79.0% | $0.14 | ~17,000 | 1M tokens |
| GLM-5.1 | SWE-Bench Pro 58.4% | ~$1.50 | ~1,600 | 200K tokens |
| Qwen3.5 Plus | — | $0.08 | ~30,000 | — |
| MiniMax M2.5 | — | $0.03 | up to 100K/month | — |
(Requests per 5-hour window calculated at roughly 2,500 average tokens per request.)
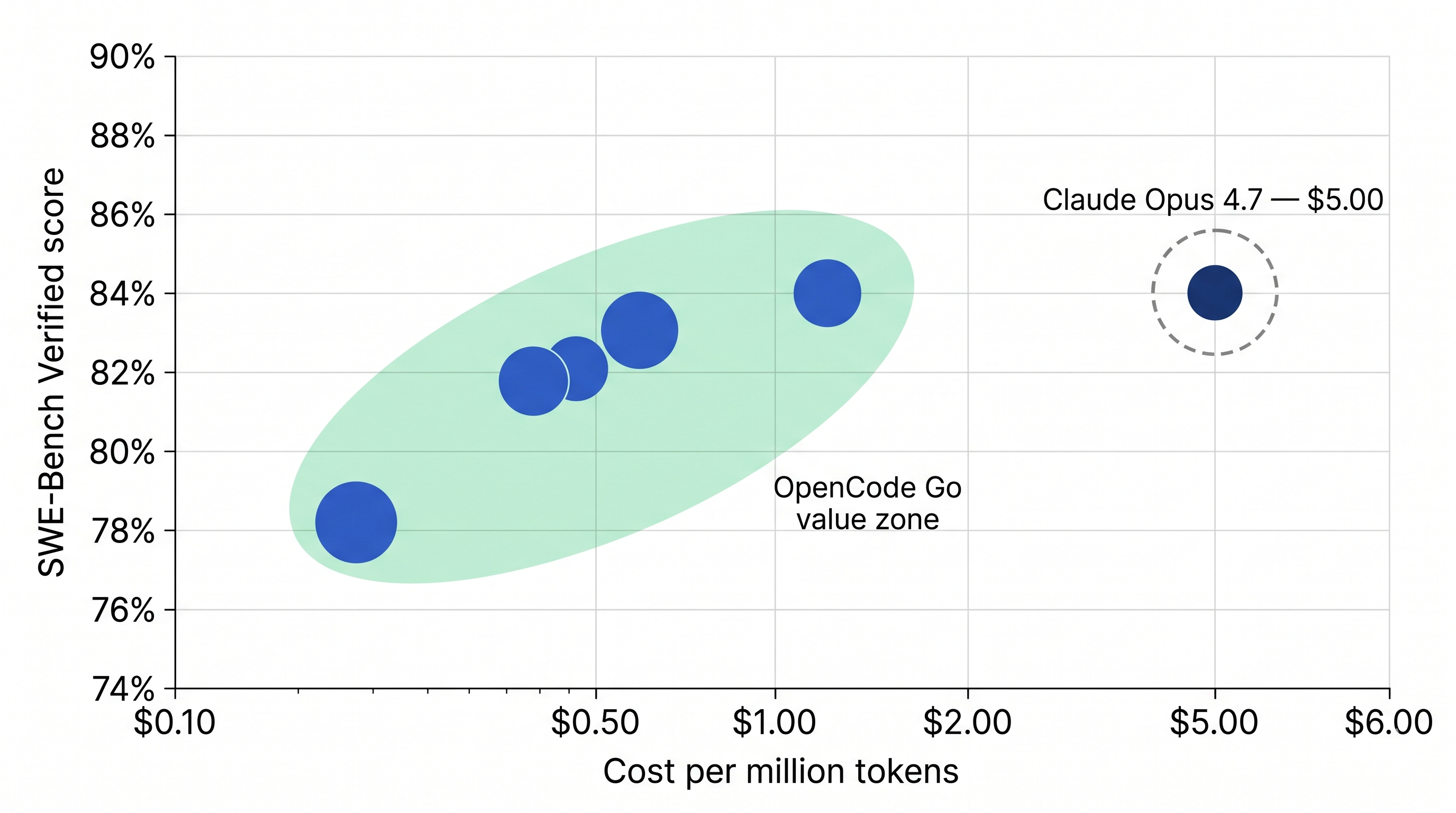
Note: Kimi K2.6 original series was discontinued on May 25, 2026. The model itself stays available but the series is no longer receiving updates. Also: DeepSeek V4 Pro's promotional pricing ($0.435/M) ends May 31 — after that the price increases, which changes the requests-per-window math.
A few things stand out. Claude Opus 4.7 at 87.6% is genuinely the strongest model available for coding tasks right now, 7 points above V4 Pro. But at $5/M tokens, it costs 35x more than DeepSeek V4 Flash per token. Within the $12/5hr window, you get around 480 Opus 4.7 requests vs 17,000 Flash requests.
DeepSeek V4 Flash sits within one point of V4 Pro in benchmark performance but at about 3x lower cost per token. For most routine coding tasks, that gap does not show up in practice. V4 Flash runs 284B total parameters with 13B active. V4 Pro runs 1.6T total with 49B active.
Kimi K2.6 is a 1-trillion-parameter MoE model with 32B active parameters, 80.2% SWE-Bench Verified. That puts it above Qwen3.6 Plus and close to V4 Pro, making it the right choice for genuinely hard multi-step reasoning when V4 Flash stalls.
GLM-5.1 sits at 744B total / 40B active. Its 200K context makes it suitable for deep planning tasks, and it handles the Oracle and Prometheus roles well at a mid-range cost point.
How Oh My OpenAgent is structured
Oh My OpenAgent v4.2.3 (as of May 2026, with 48K+ GitHub stars) uses a 3-layer architecture:
Planning Layer handles strategic decomposition and knowledge synthesis. Two agents: Prometheus (breaks down what needs to happen) and Metis (synthesizes context and prior knowledge).
Orchestration Layer is Atlas. It maintains a todo-list, enforces sequencing, and tracks completion. It does not do the work itself. It manages what gets done in what order.
Execution Layer is where the work happens. Sisyphus is the default orchestrator with a 32K extended thinking budget. Nine or more specialized agents handle specific task types.
v4.0.0 introduced Team Mode, which activates 7 additional hooks (61 total vs 54 in standard mode). Team Mode is worth enabling if you are running parallel workstreams. It is off by default.
The routing configuration
This is the community-recommended agent-to-model assignment. It is the result of a lot of trial and error, not theory:
| Agent | Primary Model | Fallback |
|---|---|---|
| Sisyphus | Kimi K2.6 | DeepSeek V4 Pro, then Qwen3.6 Plus |
| Hephaestus | DeepSeek V4 Pro | DeepSeek V4 Flash, then Kimi K2.6 |
| Oracle | GLM-5.1 | Kimi K2.6, then DeepSeek V4 Pro |
| Librarian | DeepSeek V4 Flash | Qwen3.5 Plus |
| Explore | DeepSeek V4 Flash | none |
| Prometheus | GLM-5.1 | Qwen3.6 Plus, then DeepSeek V4 Pro |
| Metis | Qwen3.6 Plus | DeepSeek V4 Pro |
| Atlas | DeepSeek V4 Pro | DeepSeek V4 Flash |
| Code-reviewer | Kimi K2.6 | DeepSeek V4 Pro |
| Multimodal-Looker | MiMo-V2.5-Pro | Qwen3.6 Plus |
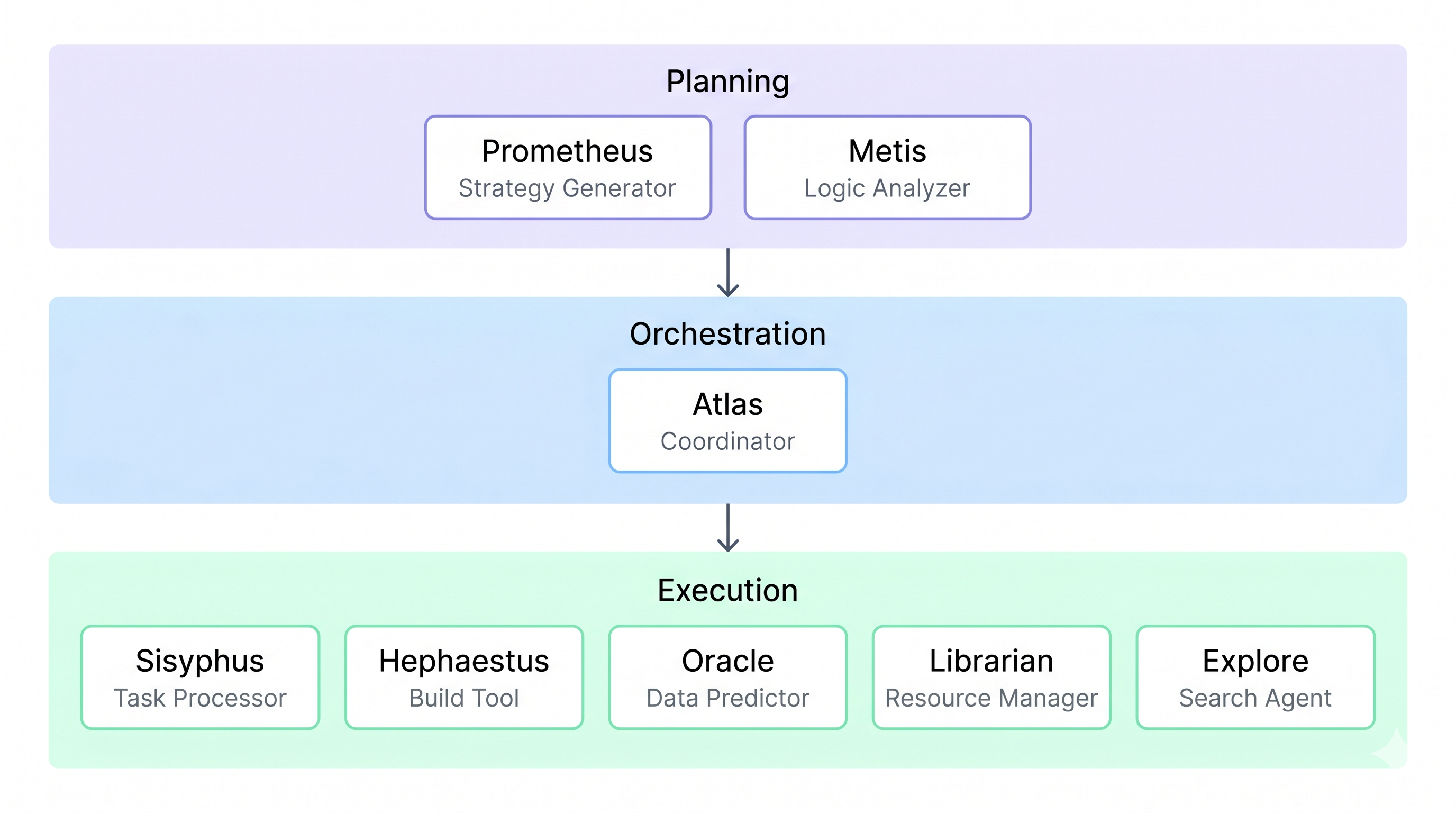
The logic behind these assignments:
Sisyphus gets Kimi K2.6 because it runs extended thinking at up to 32K tokens. You want the strongest reasoning model here, even at lower volume. Kimi's 256K context window handles long execution traces.
Librarian and Explore get V4 Flash. These agents read docs, fetch context, and do lookup work. They do not need frontier-level reasoning. Wasting V4 Pro on Librarian is the single most common budget mistake I see.
Oracle and Prometheus both get GLM-5.1. Planning and deep reasoning are where GLM-5.1 earns its slot. It is not the cheapest model, but it is not the most expensive either, and it performs well on the kinds of open-ended decomposition tasks these agents handle.
Hephaestus (the primary coding agent) gets V4 Pro as primary with V4 Flash as fallback. The gap between them is small enough that on simpler coding tasks, falling back to Flash costs you nothing visible.
MiMo-V2.5-Pro on Multimodal-Looker is deliberate. It scored 78.9% on SWE-Bench Verified and is specifically designed for agentic workflows. That specialization shows up in vision tasks and multimodal context reading.
The routing decision rule
The community consensus on routing is simple:
Route through V4 Flash first for any task that will exceed 100 requests. Escalate to Kimi K2.6 or V4 Pro only if V4 Flash gets stuck.
This works because V4 Flash at 79.0% SWE-Bench Verified handles the majority of real-world coding tasks correctly. The one-point gap to V4 Pro is real but rarely shows up unless you are hitting genuinely hard tickets. When it does, the fallback chain handles it.
Do not escalate preemptively. Let the model fail first, then escalate. Preemptive escalation is how you burn through your window in an hour.

What $10/month actually buys
At $60/month hard cap (the monthly ceiling), here is the math:
- ~5 active hours per day across 5 working days = 25 hours of active window time
- Each 5-hour window: $12 budget
- Routed correctly, a typical Oh My OpenAgent session on a medium-complexity feature might use 400-600 requests, weighted toward V4 Flash and Qwen3.5 Plus
In practice: you can run 8-12 substantial coding sessions per month before feeling the ceiling, assuming you are not doing bulk automation. For individual developer use, $10/month is genuinely enough. OpenCode hit 150K GitHub stars in May 2026 in part because that math works out.
The realistic comparison: Claude API at similar quality levels would cost $150-300/month for the same volume. That is where the 10-20x cost reduction claim comes from, and in my experience it holds.
The honest trade-off
The gap between this stack and Claude Opus 4.7 on real-world bug fixes is about 7 percentage points. That is real. Some tickets require multiple iterations where Claude would have gotten it right once. Budget for that.
One thing pushes back on that framing: the 7-point gap is an average across all task types. On well-scoped tickets with clear acceptance criteria, the gap narrows significantly. The routing configuration is specifically designed to escalate to Kimi K2.6 or V4 Pro on the tasks where that gap is most likely to show up.
Where this stack genuinely struggles: ambiguous requirements, complex multi-file refactors with implicit dependencies, and tasks that require understanding undocumented system behavior. On those, premium models earn their cost. The routing configuration handles this by putting Kimi K2.6 on the hardest tasks, but Kimi has a 256K context window vs Qwen3.6 Plus's 1M, so very long context tasks may require a different allocation.
The actual configuration
Two files control everything: opencode.json at your project root, and .omc/config.json for Oh My OpenAgent routing. Here is both.
opencode.json — base OpenCode configuration with all available models declared:
{
"$schema": "https://opencode.ai/config.schema.json",
"theme": "opencode",
"autoshare": false,
"model": "deepseek-v4-flash",
"providers": {
"opencode": {
"models": [
"deepseek-v4-pro",
"deepseek-v4-flash",
"kimi-k2.6",
"glm-5.1",
"qwen3.6-plus",
"qwen3.5-plus",
"mimo-v2.5-pro",
"minimax-m2.5"
]
}
}
}The "model" field sets your default — V4 Flash is the right default because it handles most tasks at lowest cost.
.omc/config.json — Oh My OpenAgent routing assignments:
{
"version": "4.2.3",
"teamMode": false,
"agents": {
"sisyphus": {
"model": "kimi-k2.6",
"fallback": ["deepseek-v4-pro", "qwen3.6-plus"],
"thinkingBudget": 32000
},
"hephaestus": {
"model": "deepseek-v4-pro",
"fallback": ["deepseek-v4-flash", "kimi-k2.6"]
},
"oracle": {
"model": "glm-5.1",
"fallback": ["kimi-k2.6", "deepseek-v4-pro"]
},
"prometheus": {
"model": "glm-5.1",
"fallback": ["qwen3.6-plus", "deepseek-v4-pro"]
},
"metis": {
"model": "qwen3.6-plus",
"fallback": ["deepseek-v4-pro"]
},
"atlas": {
"model": "deepseek-v4-pro",
"fallback": ["deepseek-v4-flash"]
},
"librarian": {
"model": "deepseek-v4-flash",
"fallback": ["qwen3.5-plus"]
},
"explore": {
"model": "deepseek-v4-flash",
"fallback": []
},
"code-reviewer": {
"model": "kimi-k2.6",
"fallback": ["deepseek-v4-pro"]
},
"multimodal-looker": {
"model": "mimo-v2.5-pro",
"fallback": ["qwen3.6-plus"]
}
},
"routing": {
"escalationPolicy": "on-failure",
"budgetAlert": 10.00,
"windowBudget": 12.00
}
}The escalationPolicy: "on-failure" key is the important one. It enforces the routing rule from above: models escalate only when the primary fails, not preemptively. budgetAlert triggers a warning at $10 so you know you have $2 left in the window before the ceiling hits.
To enable Team Mode after setup, flip "teamMode": true and restart. It activates 7 additional hooks (61 total) for parallel workstream coordination.
Quick start
# Install OpenCode Go
npm install -g opencode
# Install Oh My OpenAgent
npx omc install oh-my-openagent
# Create opencode.json and .omc/config.json from the templates above, then:
omc init --preset oh-my-openagentTo check your current window spend:
opencode usage --window currentThat last command is more useful than it sounds. Knowing where you are in the $12 window changes how aggressively you escalate to premium models.
For a deeper walkthrough of the original configuration approach, the guide that got me started is Jatin Malik's post: OpenCode Go + Oh My OpenAgent: The Complete Guide to SOTA Model Routing Without Hitting Limits. It covers some of the earlier v4.0-v4.1 configuration in detail and is worth reading alongside this.
Interested in working together?