FreeLLM
ShippedOpenAI-compatible gateway that pools 6 free LLM tiers into one endpoint. Multi-key rotation, circuit breakers, response cache.
6
Providers
~360 RPM
Free Capacity
SHA-256
Cache Layer
$0
Cost
The Problem
Every free LLM tier rate-limits you within an hour of real use. Groq gives 30 RPM, Gemini gives 15, Mistral gives 1. To ship anything you end up juggling 4 SDKs, 4 sets of keys, and 4 different error shapes. Switch providers and your client code changes. Hit a 429 and your app stops. Nobody wants to write that plumbing again.
What I Built
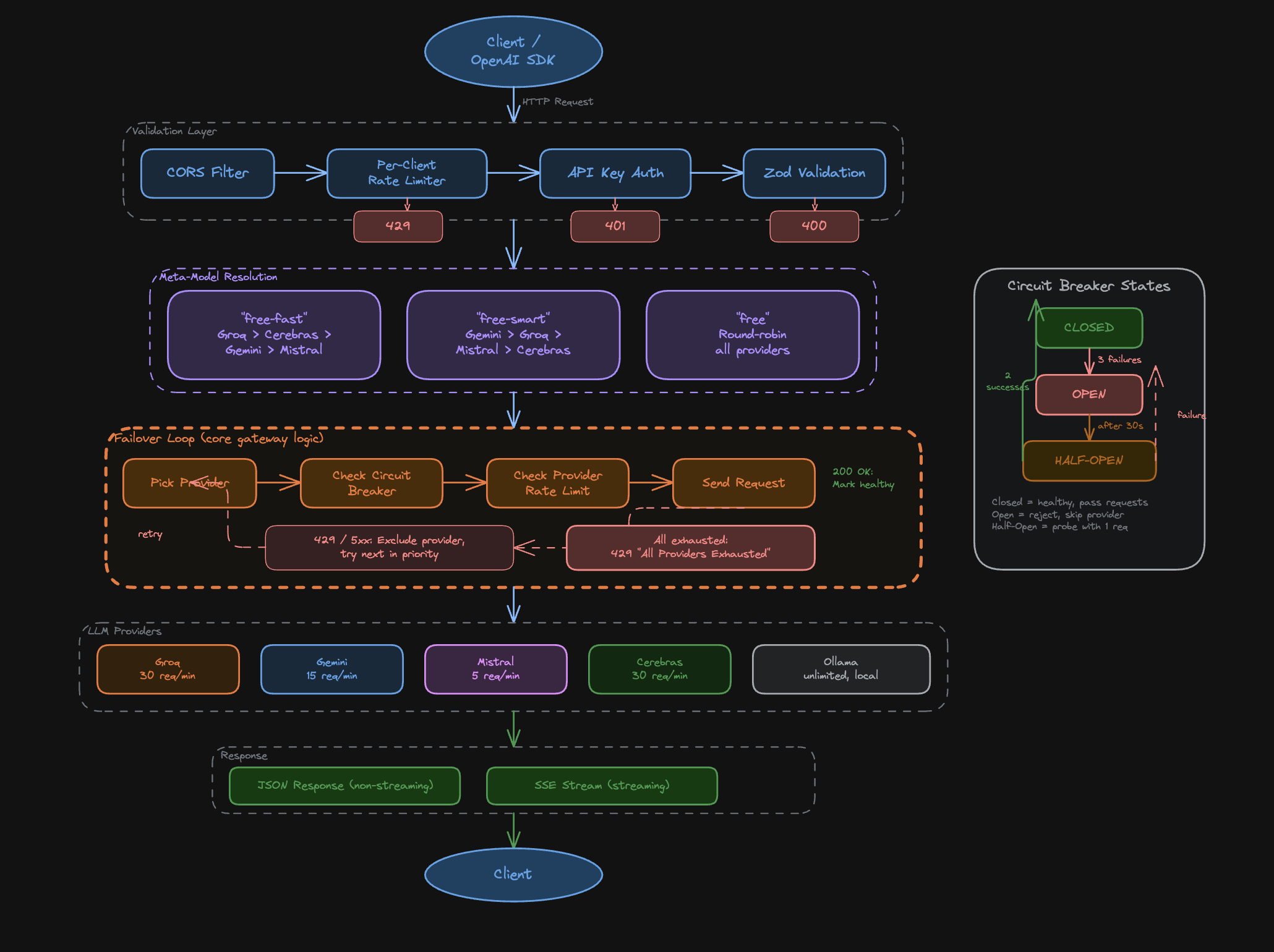
OpenAI-Compatible Gateway
Speaks the full Chat Completions API spec: streaming, function calling, JSON mode, system prompts, and multi-turn. Existing OpenAI clients work with a one-line baseURL change. No SDK swap needed.
Virtual Model Routing
Three virtual models (free-fast, free-smart, free) abstract away provider choice. free-fast routes to Groq first for sub-100ms latency. free-smart routes to Gemini for reasoning tasks. free picks the cheapest available provider. Routing logic is a priority queue with fallback chains.
Circuit Breaker Resilience
Each provider has an independent circuit breaker with CLOSED/OPEN/HALF-OPEN states. After 5 consecutive errors, the circuit opens for 30 seconds. A background health checker probes the HALF-OPEN state every 10 seconds. Failed requests never surface to the client.
Multi-Key Rotation
Each provider accepts up to 10 API keys. The router round-robins across keys per request, multiplying free quota linearly. Groq at 30 RPM with 3 keys becomes 90 RPM. Key health is tracked independently so a dead key is skipped automatically.
SHA-256 Response Cache
Identical prompts hash to the same SHA-256 key and return the cached response in under 1ms. Cache TTL is configurable per model. Streaming responses are cached as chunked arrays and replayed identically. Cuts repeat-prompt cost to zero for deterministic workloads.
Architecture
Tech Stack
All projects- TypeScript
- Express 5
- Node.js 22
- React
- Vite
- Tailwind CSS
- Astro Starlight
- Zod
- Docker
Read the writeup: FreeLLM on the blog
Related Projects
Interested in working together?