LiteLLM Got Hacked. I Built a Simpler LLM Gateway You Can Actually Audit.
The most popular LLM routing library got compromised in a supply chain attack. 95 million monthly downloads. Credential harvester, Kubernetes backdoor, persistent RCE. I built FreeLLM as a narrower, auditable alternative: 6 providers, 262 tests, one job.
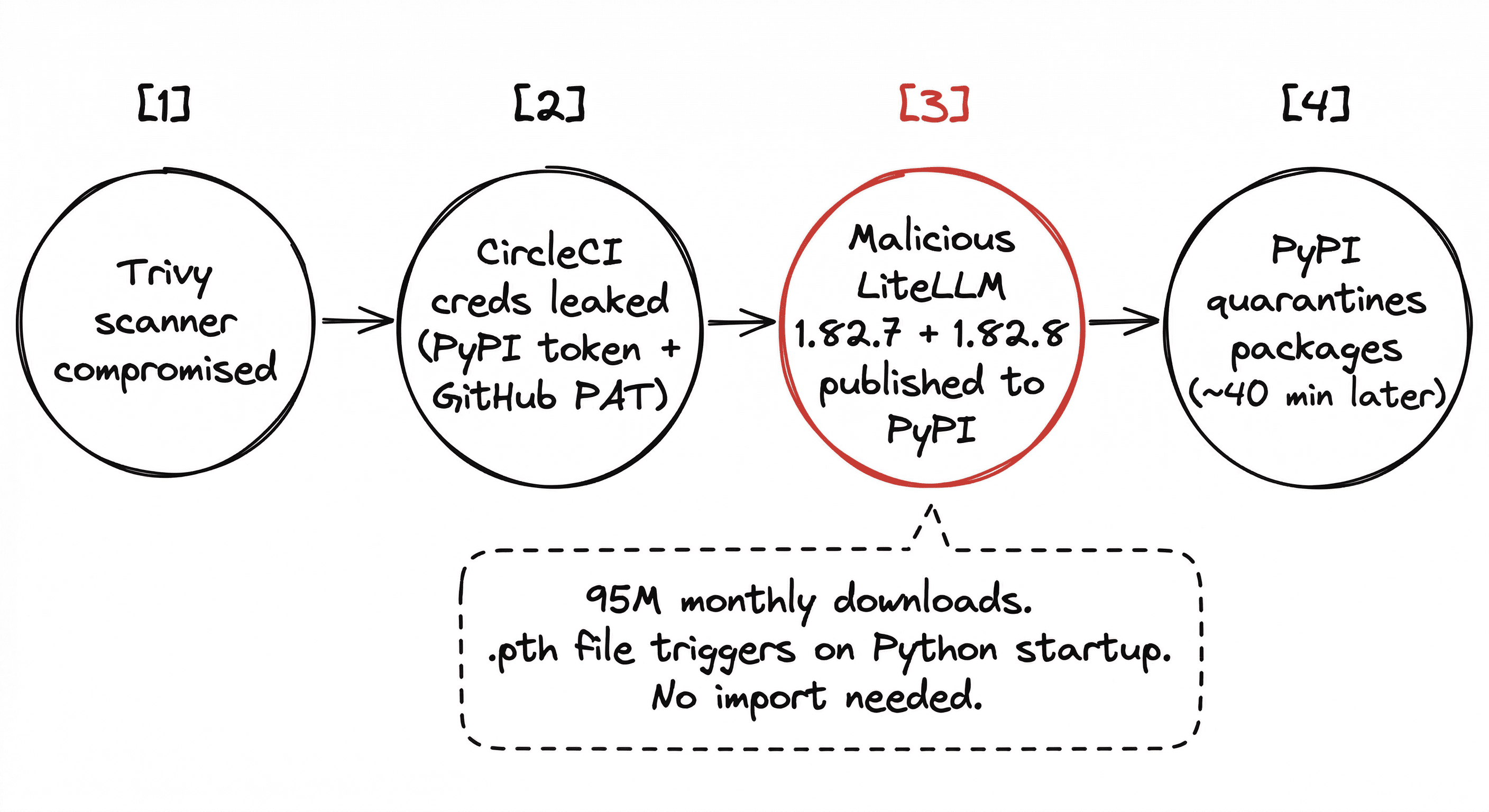
On March 24, 2026, LiteLLM versions 1.82.7 and 1.82.8 were uploaded to PyPI with malware baked into them.
A credential harvester targeting 50+ secret categories. A Kubernetes lateral-movement toolkit. A persistent remote code execution backdoor. All triggered on Python interpreter startup via a .pth file. You didn't need to import the library. Having it installed was enough.
PyPI quarantined the packages in about 40 minutes. But LiteLLM gets 95 million downloads a month. Google brought in Mandiant. Snyk, Kaspersky, and Trend Micro all published breakdowns.
The attack vector: a compromised Trivy security scanner leaked CircleCI credentials, including the PyPI publishing token and a GitHub PAT. From there, the attacker uploaded the poisoned versions directly.
The real problem is scope
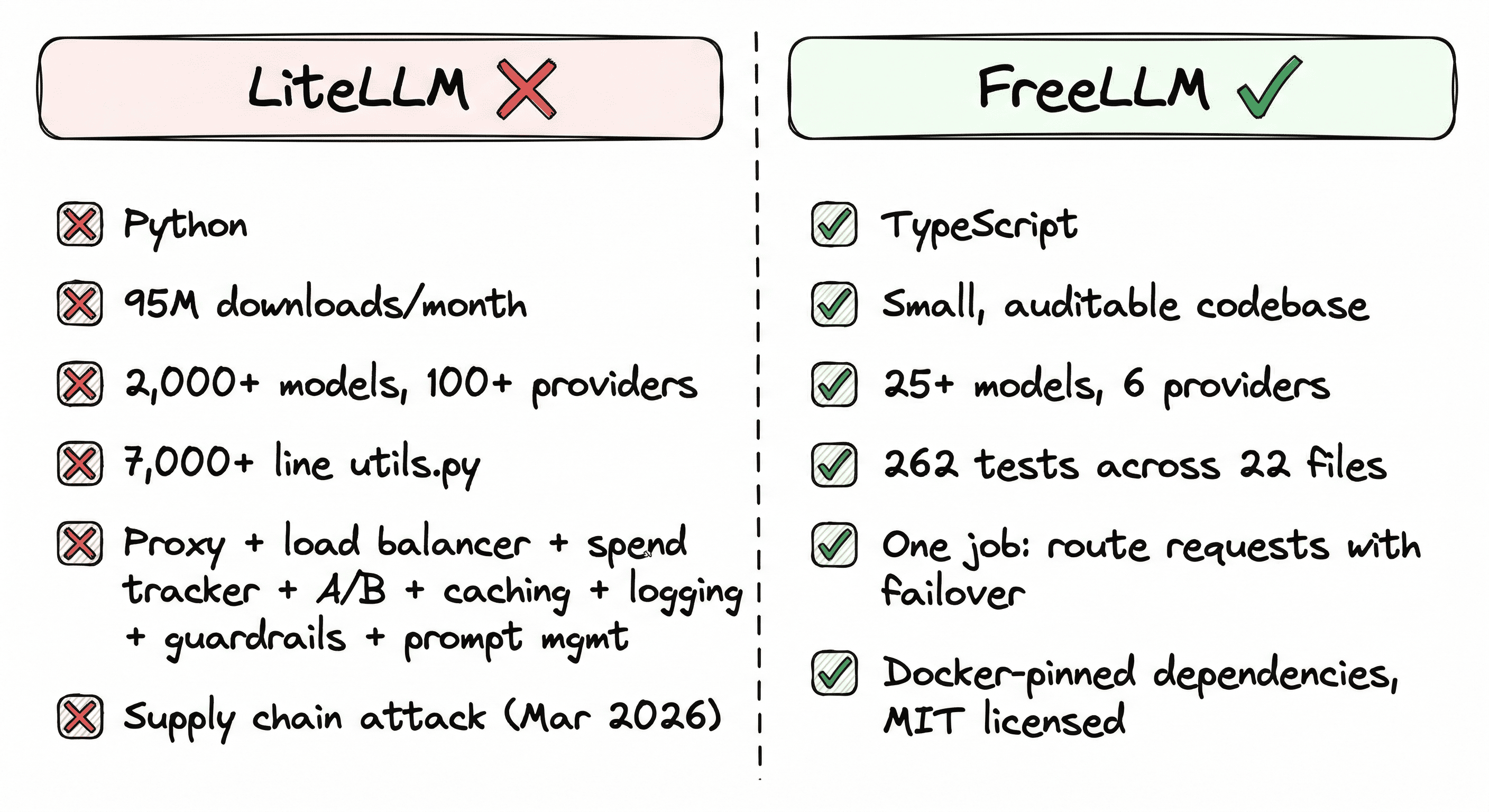
LiteLLM does a lot. 2,000+ models across 100+ providers. Proxy server, load balancing, spend tracking, A/B testing, caching, logging, guardrails, prompt management.
Every feature is more code to maintain, more dependencies to track, more surface area to compromise. A developer on HN described a 7,000+ line utils.py. A DEV Community post documenting "5 Real Issues With LiteLLM" was circulating before the attack even happened.
The supply chain attack was the tipping point. The root cause is depending on a massive, opaque library for infrastructure that handles all your API keys.
What I built instead
I ran into the multi-provider routing problem last year while building Metis. Kept burning through Groq's free tier in 20 minutes of testing. Switched to Gemini manually. Hit their cap. Switched to Mistral. Every time.
Built FreeLLM to stop doing that manually. It solves a narrower problem than LiteLLM, and that's the point.
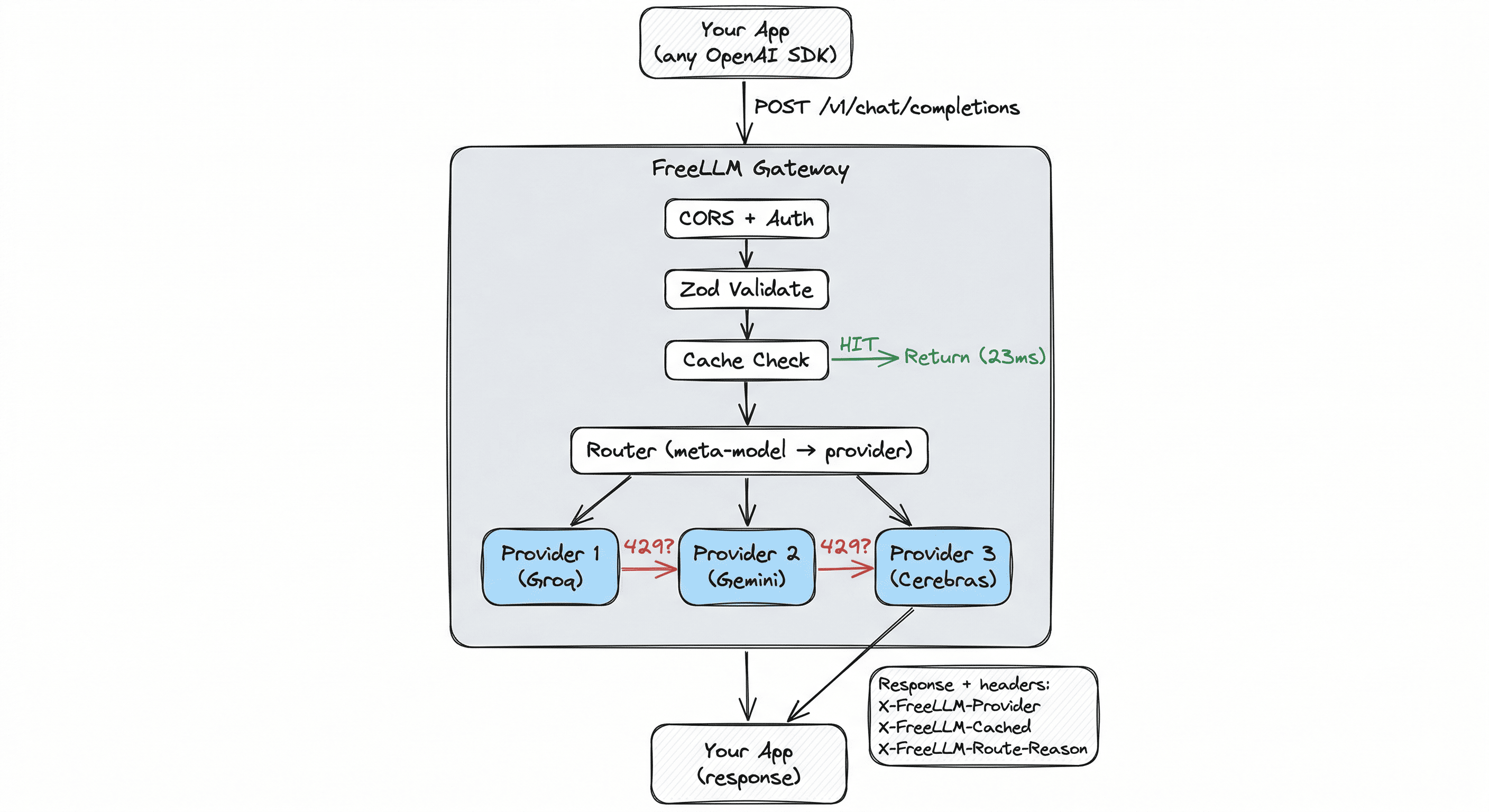
FreeLLM is an OpenAI-compatible gateway that routes across six providers: Groq, Gemini, Mistral, Cerebras, NVIDIA NIM, and Ollama. When one rate-limits, the next one answers. Circuit breakers pull failing providers from rotation. Response caching saves duplicate calls.
That's the whole scope.
curl http://localhost:3000/v1/chat/completions \
-d '{"model": "free-fast", "messages": [{"role": "user", "content": "Hello!"}]}'Your existing OpenAI SDK code works. Swap the base URL. Keep your code. Three meta-models handle routing: free-fast for speed, free-smart for reasoning, free for max availability.
What it fixes beyond routing
Gemini 2.5 silently eats your output budget
This is one of the most reported Gemini bugs right now. 15+ open GitHub issues across googleapis/python-genai, gemini-cli, LangChain, and Cline.
Gemini 2.5 Flash and Pro are reasoning models. They burn 90-98% of your max_tokens on internal thinking before producing visible text. You ask for 1,000 tokens. You get back 37. No error. No warning. Google's own documentation doesn't clearly explain this.
FreeLLM fixes it at the gateway. Flash gets reasoning_effort: "none" by default (no thinking budget, full output). Pro gets "low" (minimum Google allows). Your full token budget goes to the actual answer. Override per-request if you want reasoning back.
Before the fix: 37 tokens. After: 670+. Same prompt.
Provider outages don't break your app
Claude went down for three consecutive days in early April. 8,000+ Downdetector reports. If your app depends on one provider, that's three days of broken service.
FreeLLM's circuit breakers detect failures within seconds, pull the provider from rotation, and test for recovery automatically. Your users never see the outage.
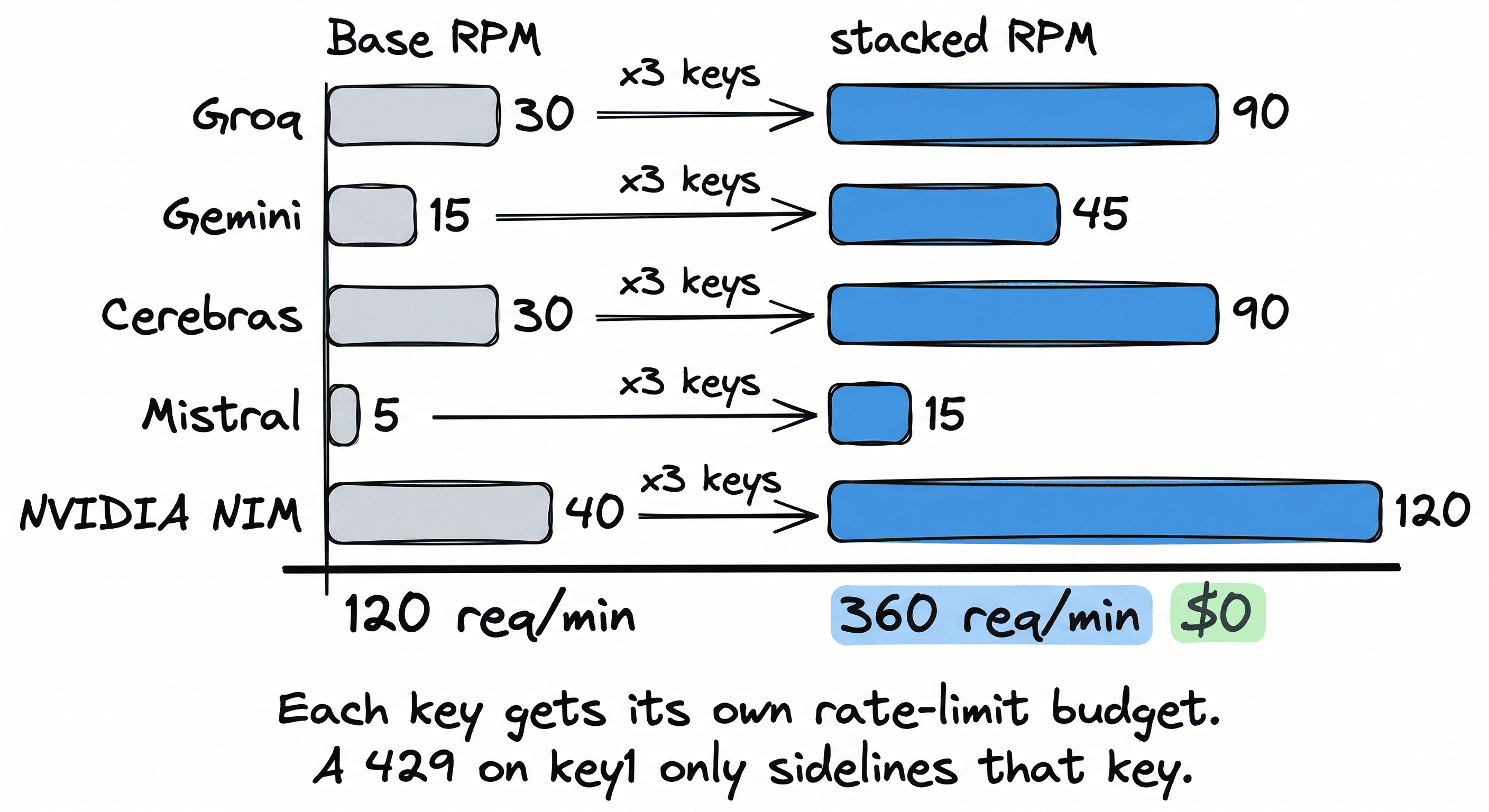
360 free requests per minute with key stacking
Every provider env var accepts comma-separated keys. FreeLLM rotates round-robin, each key getting its own rate-limit budget.
| Provider | Base RPM | x3 keys | Stacked RPM |
|---|---|---|---|
| Groq | 30 | x3 | 90 |
| Gemini | 15 | x3 | 45 |
| Cerebras | 30 | x3 | 90 |
| Mistral | 5 | x3 | 15 |
| NVIDIA NIM | 40 | x3 | 120 |
| Total | 120 | 360 req/min |
All free. Enough to prototype an entire product before spending anything.
Browser-safe tokens for static sites
Want to drop an AI chatbot into a static site? Mint a short-lived HMAC-signed token from a one-file serverless function. Pass it to the browser. Call the gateway directly from client-side JavaScript. No auth backend. No session store. Origin-bound, 15-minute TTL, per-user rate limiting.
Response caching done right
Identical prompts return in ~23ms with zero quota burn. The cache refuses to store truncated responses. This matters because Gemini's reasoning models can return cut-off output that then poisons your cache for the entire TTL window.
The auditability argument
FreeLLM is 262 tests across 22 files. TypeScript, not Python. You can read the entire routing logic in an afternoon.
Docker images pin every dependency. No .pth files. No auto-executing code on import. No 7,000-line utility files.
This is not just about FreeLLM. The principle applies everywhere: smaller dependencies, pinned versions, codebases you can actually read. The era of "install this 100-provider mega-library and trust it with your API keys" should be over.
Get started
Docker:
docker run -d -p 3000:3000 \
-e GROQ_API_KEY=gsk_... \
-e GEMINI_API_KEY=AI... \
ghcr.io/devansh-365/freellm:latestOr one-click deploy: Railway and Render buttons in the README.
Use with any OpenAI SDK:
from openai import OpenAI
client = OpenAI(base_url="http://localhost:3000/v1", api_key="unused")
response = client.chat.completions.create(
model="free-smart",
messages=[{"role": "user", "content": "Explain circuit breakers"}]
)TypeScript, Go, Ruby, anything that speaks OpenAI. Same pattern.
262 tests. 6 providers. One endpoint. Zero cost. MIT licensed.
GitHub: github.com/devansh-365/freellm
Docs: freellms.vercel.app
You can also check out my other projects or read about how I validated Metis before writing code.
Related: I Built an OpenAI-Compatible Gateway That Routes Across 5 Free LLM Providers
Interested in working together?