Gemini 2.5 Flash Was Returning 37 Tokens. Here's Why.
I set max_tokens=1000 on a Gemini 2.5 Flash call. Got back 37 tokens. No error, no warning. The real cause was reasoning tokens eating the output budget, a bug documented in 15+ open GitHub issues but missing from every tutorial. Here is the full debugging trail, the three-tier fix with tradeoffs, and a diagnostic script.
I set max_tokens: 1000 on a Gemini 2.5 Flash call.
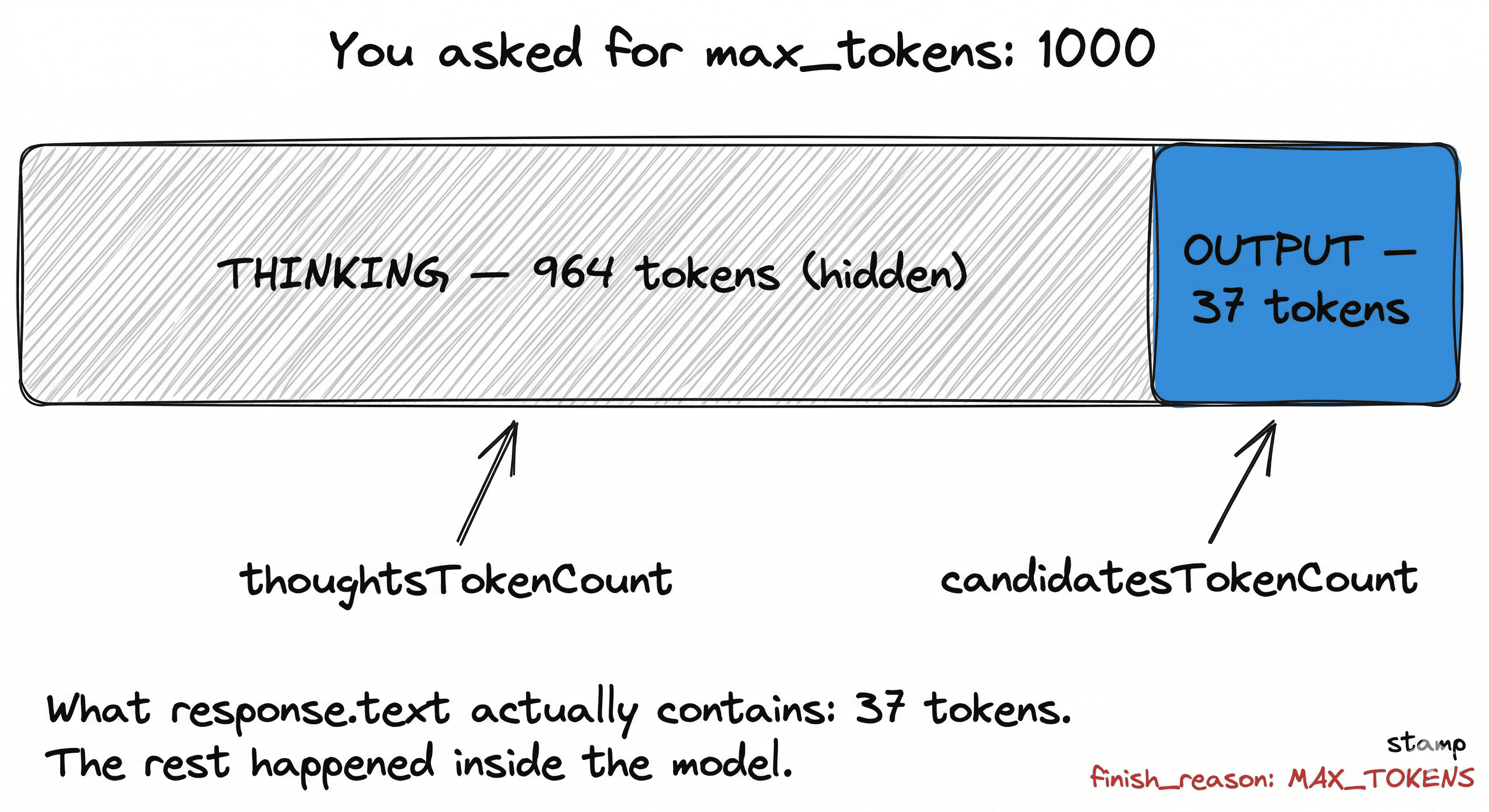
The response came back with 37 tokens. finish_reason: "MAX_TOKENS". No error. No warning. Just a string that stopped mid-sentence.
I changed it to 2000. Got back 41 tokens. Then 5000. Got back 38.
That's when I knew something was actually broken.
I spent a day tracing this. The root cause is surprising, the official docs don't explain it clearly, and the fix depends on which SDK you're using. Here's what I learned, plus a diagnostic script so you can figure out which variant of the bug you're hitting.
The symptom
Your Gemini 2.5 Flash or Pro call returns something like this:
{
"candidates": [{
"content": { "parts": [{ "text": "" }] },
"finishReason": "MAX_TOKENS"
}],
"usageMetadata": {
"promptTokenCount": 120,
"candidatesTokenCount": 0,
"thoughtsTokenCount": 964,
"totalTokenCount": 1084
}
}Or a truncated mid-sentence response with candidatesTokenCount near zero and thoughtsTokenCount close to your max_output_tokens.
The word thoughtsTokenCount is the giveaway.
Why it happens
Gemini 2.5 Flash and Pro are reasoning models. Like OpenAI's o-series, they burn tokens on internal reasoning before writing the visible response. Unlike OpenAI, Google counts those thinking tokens against your max_output_tokens budget.
When you ask for 1,000 tokens:
- The model thinks. Tokens tracked as
thoughtsTokenCount. - Once
thoughtsTokenCount + candidatesTokenCounthits your budget, generation stops. - If thinking consumed most of the budget,
candidatesTokenCountends up near zero.
Gemini 2.5 Flash defaults to a dynamic thinking budget. It decides how much to think based on the task. For anything non-trivial, it will happily burn 90 to 98 percent of your budget on reasoning.
This is documented across 15+ open GitHub issues spanning Google's own SDK, gemini-cli, LangChain, LiteLLM, and integrations like ha-llmvision. One developer in the python-genai repo summarized it exactly: "When I get FinishReason.MaxTokens, thoughts_token_count equals max_output_tokens."
The three fixes, ranked
There are three ways to handle this, and they have real tradeoffs.
| Fix | Latency | Cost | Quality | Best for |
|---|---|---|---|---|
Disable thinking (thinking_budget: 0 or reasoning_effort: "none") | Fast | Low | Lower on complex reasoning | Chat UIs, structured extraction, high-volume endpoints |
Cap thinking (thinking_budget: 1024 + max_output_tokens: 8192) | Medium | Medium | Good | Most production workloads |
| Dynamic thinking (default, large budget) | Slowest | Highest | Best | Research queries, complex analysis |
The third option is the default, and it's the source of the bug. It's only the right choice if you're actually okay with burning most of your tokens on reasoning and waiting 5 to 30 seconds per response.
Fix 1: Disable thinking for Flash
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model="gemini-2.5-flash",
contents="Explain circuit breakers in 2 sentences.",
config=types.GenerateContentConfig(
max_output_tokens=1000,
thinking_config=types.ThinkingConfig(thinking_budget=0)
)
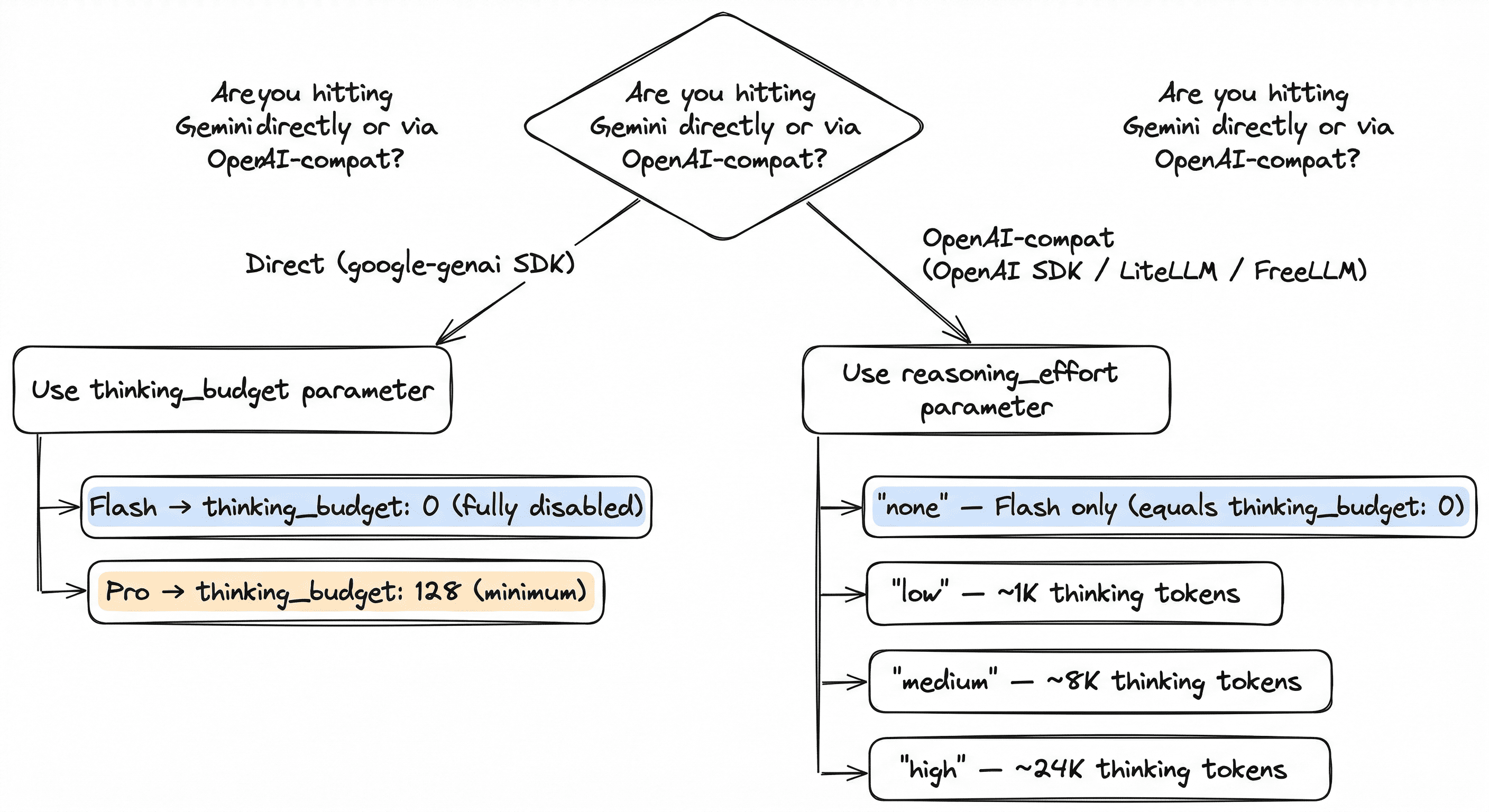
)thinking_budget=0 is only valid for 2.5 Flash. Pro refuses to run without at least some thinking and throws: Thinking can't be disabled for this model. For Pro, the minimum accepted value is 128.
Fix 2: The OpenAI-compat escape hatch (underdocumented)
If you're hitting Gemini through the OpenAI-compatible endpoint, you can use reasoning_effort instead of thinking_budget:
from openai import OpenAI
client = OpenAI(
base_url="https://generativelanguage.googleapis.com/v1beta/openai",
api_key=GEMINI_API_KEY
)
response = client.chat.completions.create(
model="gemini-2.5-flash",
messages=[{"role": "user", "content": "Explain circuit breakers"}],
max_tokens=1000,
reasoning_effort="none" # or "low", "medium", "high"
)This is barely documented. Google's compatibility page mentions it in passing, and almost no tutorials cover it. But it works, and it's the cleanest way to control reasoning from OpenAI-SDK code.
Mapping:
reasoning_effort: "none"→thinking_budget: 0(Flash only)reasoning_effort: "low"→thinking_budget: 1024reasoning_effort: "medium"→thinking_budget: 8192reasoning_effort: "high"→thinking_budget: 24576
Fix 3: Integration-specific gotchas
LangChain silently truncates output. Developers report setting max_tokens=16000 and still getting cut-off responses. Pass thinking_budget via model_kwargs, or switch to the OpenAI-compat endpoint through ChatOpenAI.
LiteLLM accepts reasoning_effort and maps it to the Gemini parameter, but as of late 2025 it rejected reasoning_effort: "none" for Pro. Use "low" instead.
ha-llmvision defaulted thinkingBudget to 35 to 50 tokens, which gets fully consumed by thinking. Set to 1024 or higher.
Cline set thinkingBudget: 0, which works for Flash Lite but throws on Pro. Fix depends on target model.
Vertex AI uses thinkingConfig.thinkingBudget nested inside the config object. Raw API requests that put it at the top level silently ignore it.
Diagnostic script
If you're not sure which variant of the bug you hit, run this:
from google import genai
client = genai.Client()
def diagnose(model: str, prompt: str, max_tokens: int):
response = client.models.generate_content(
model=model,
contents=prompt,
config={"max_output_tokens": max_tokens}
)
usage = response.usage_metadata
text = response.candidates[0].content.parts[0].text or ""
finish = response.candidates[0].finish_reason
thinking_pct = (usage.thoughts_token_count / max_tokens * 100) if usage.thoughts_token_count else 0
output_pct = (usage.candidates_token_count / max_tokens * 100) if usage.candidates_token_count else 0
print(f"Model: {model}")
print(f"Budget: {max_tokens}")
print(f"Thinking used: {usage.thoughts_token_count} ({thinking_pct:.0f}%)")
print(f"Output tokens: {usage.candidates_token_count} ({output_pct:.0f}%)")
print(f"Finish reason: {finish}")
print(f"Response len: {len(text)} chars")
if finish == "MAX_TOKENS" and usage.candidates_token_count < max_tokens * 0.1:
print("\nDIAGNOSIS: Thinking tokens ate your budget.")
print("FIX: Set thinking_budget=0 (Flash) or reasoning_effort='none'.")
elif finish == "MAX_TOKENS":
print("\nDIAGNOSIS: Output actually hit the cap. Raise max_output_tokens.")
diagnose("gemini-2.5-flash", "Write a short poem about debugging.", 200)The script prints a percentage breakdown showing exactly where your budget went. If thinking is over 50 percent of your budget, you need to cap it.
The gateway-level fix
All of this is fixable at the application layer, but it requires every caller to know about reasoning budgets. That doesn't scale across services.
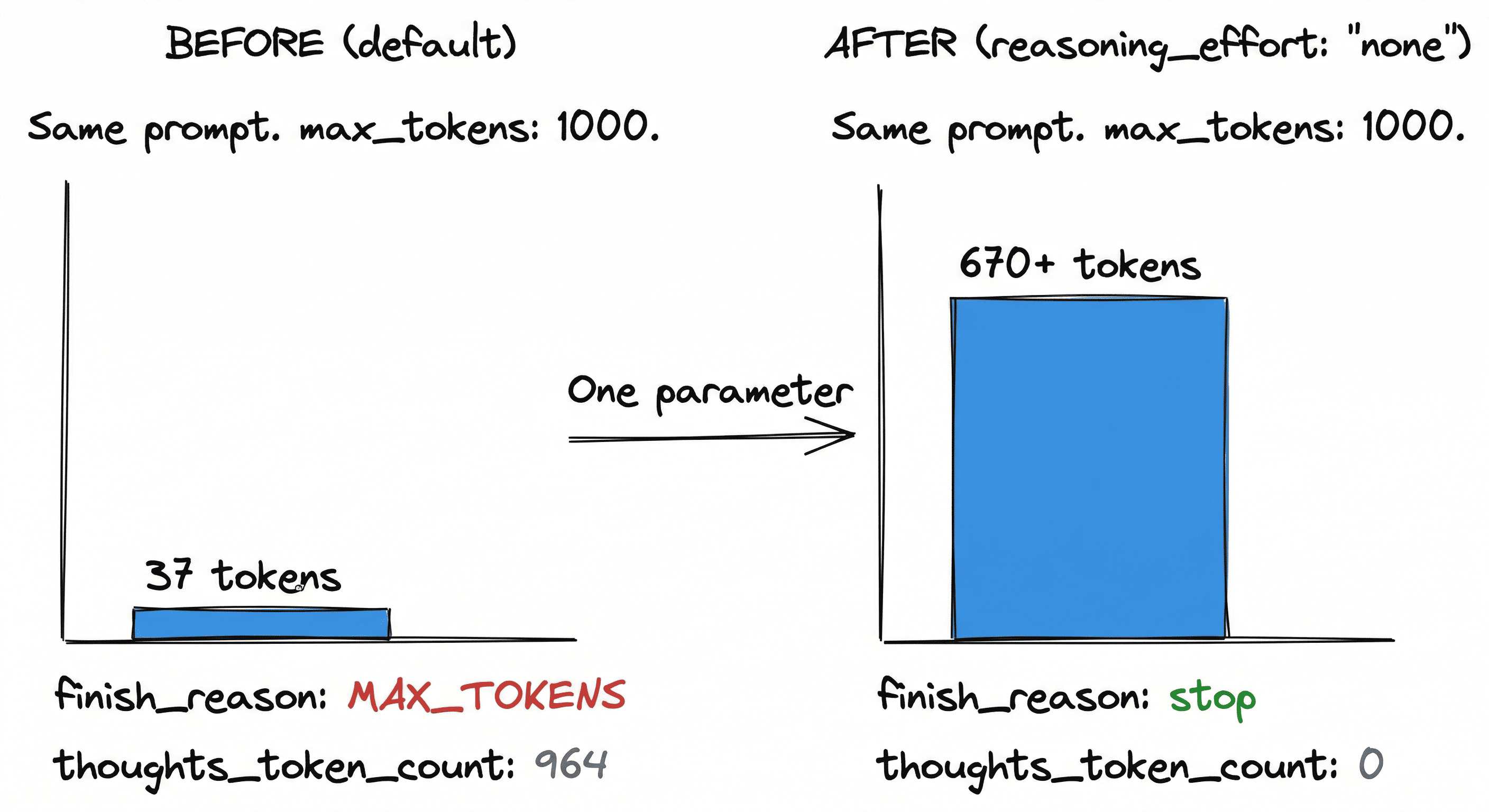
I run FreeLLM in front of my LLM calls. It's an OpenAI-compatible gateway that routes across six providers, and it sets the right reasoning budget per Gemini model automatically. Flash gets reasoning_effort: "none". Pro gets "low". Your full max_tokens budget goes to the actual answer. Override per request if you need reasoning back.
curl http://localhost:3000/v1/chat/completions \
-d '{
"model": "gemini/gemini-2.5-flash",
"messages": [{"role": "user", "content": "Hello"}],
"max_tokens": 1000
}'Before the gateway: 37 output tokens. After: 670+ tokens, finish_reason: stop. Same prompt, same budget.
The point is not "use my tool." The point is that gateway-level defaults let you fix provider quirks once instead of in every service.
Takeaways
- Gemini 2.5 is a reasoning model. Its thinking tokens count against your
max_output_tokens. - The dynamic default will eat 90 to 98 percent of your budget on anything non-trivial.
- For Flash, disable thinking with
thinking_budget: 0orreasoning_effort: "none". - For Pro, cap thinking with
thinking_budget: 128(minimum) orreasoning_effort: "low". - If you're using an OpenAI-compat endpoint,
reasoning_effortis cleaner and underdocumented. - Run the diagnostic script when in doubt.
The official docs don't make any of this obvious. Hopefully this post saves you the day I lost to it.
FreeLLM on GitHub: github.com/devansh-365/freellm — the gateway that handles this for you.
You can also read about why I ditched LiteLLM after the supply chain attack or how I validated Metis before writing code.
Interested in working together?