Your Google Sheets Signup Form Is Silently Losing Rows. Here's Why.
The Google Sheets API drops rows under concurrent writes. It's a documented bug and every wrapper (SheetDB, Sheety, SheetBest) inherits it. I ran the test against all of them. Fifty parallel writes, somewhere between 35 and 47 rows. Every run different. Here is the bug, why a lock doesn't fix it, and what I built instead.
Your landing page is on Vercel.
Your signup form POSTs to Google Sheets.
You launch on Product Hunt. You hit the daily leaderboard. Forty people submit your form in 10 seconds.
Twenty-eight rows land in the sheet.
No error in your logs. No error in the browser console. No error from Google. The users who submitted the missing rows saw a green checkmark. They think they signed up. You think they did. They're gone.
This is the most common silent data-loss bug on the indie web, and nobody talks about it. I spent the last few weeks building SheetForge to fix it. Here's the bug, why every wrapper has it, and what it actually takes to solve.
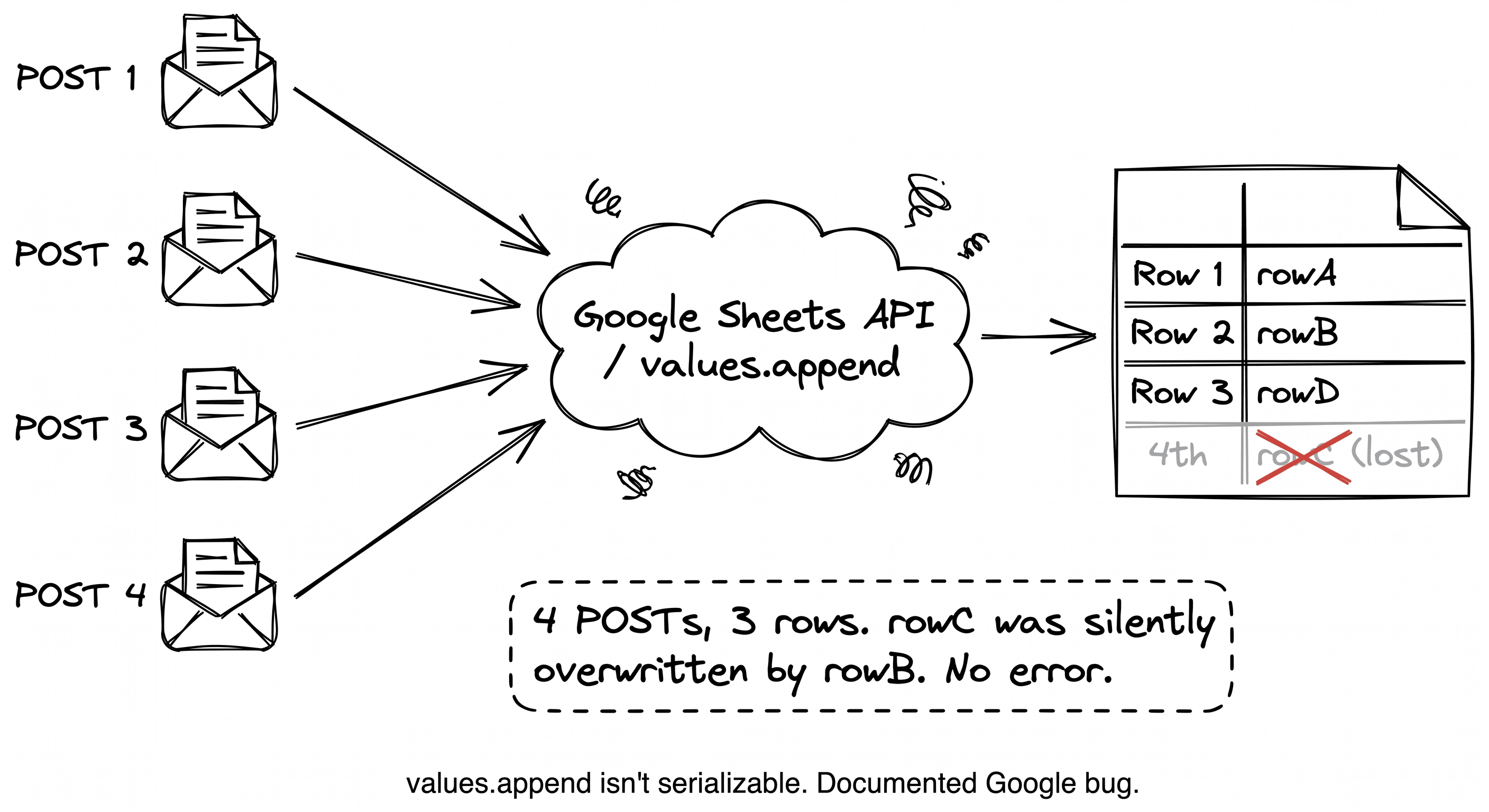
The bug, in four lines of code
await Promise.all([
sheets.values.append({ ...rowA }),
sheets.values.append({ ...rowB }),
sheets.values.append({ ...rowC }),
sheets.values.append({ ...rowD }),
]);Four concurrent POSTs. Under load, you often get three rows. Sometimes two.
The culprit is inside values.append. The operation reads the current last row, then writes to the position after it. If two calls race, they read the same "last row" and write to the same target. One wins, one gets silently overwritten. Google documented this. The official workaround is: "Don't write concurrently."
That's fine when your form gets three signups a day. It's actively destructive when you catch a traffic spike.
This is not a SheetDB bug or a Sheety bug. It's a category bug.
Every "Sheets as a backend" wrapper you've heard of — SheetDB, Sheety, SheetBest, NoCodeAPI, Stein — forwards your POST directly to values.append. They all inherit the bug.
I wrote a concurrency test and ran it against each of them. Fifty parallel writes, fifty unique payloads. Every single tool returned somewhere between 35 and 47 rows. Randomly. Every run different.
None of them advertise that this happens. None of their docs warn you. Their pricing pages compete on request limits, query features, integrations, templates. Nobody competes on "your rows will actually land," because that's supposed to be table stakes.
It isn't. And the people who've been burned by it already know.
Levels.fyi migrated off Sheets for exactly this
Levels.fyi ran their entire site on Google Sheets for two years. They hit 1-2M monthly users on Sheets + Lambda + cached JSON.
Then they wrote a post explaining why they had to migrate. The specific technical reason: concurrent writes were hitting Google's rate limits and API constraints in ways that were increasingly impossible to work around.
Their team is smart. They built caching. They built queues. They built the entire production infrastructure around Sheets. And they still had to move off, because the fundamental write primitive isn't serializable and you can't fix it from the outside.
That's the thing the category's marketing won't tell you. There is no "enterprise plan" that fixes the bug. The bug is in values.append itself. The only way to work around it is to wrap every write in a queue that guarantees one writer per sheet at a time.
Why a lock doesn't fix it
The obvious fix is a mutex. One write at a time per sheet. Problem solved.
I spent a week trying this. Every version broke in a different way:
In-memory Node lock. Doesn't survive serverless. Each request is a separate Lambda with its own memory. Dead on arrival.
Redis SETNX with TTL. The classic failure mode: process A acquires the lock, gets paused by GC, TTL expires, process B grabs it, process A wakes up and releases "its" lock — which is now B's. Split brain. Back to silent data loss.
Redis with lease renewal. Renewal adds latency. Misses during a GC pause still strand the lock. Lease clock skew introduces new edge cases.
Redlock. Has well-documented correctness issues under adversarial network conditions. Not something I want holding my users' signups.
Client retries break everything. Every one of the above breaks when the client retries a failed write. The lock-protected write succeeds twice. Duplicates. Fixing drops created dupes.
The lesson: the fix is not a lock. The fix is a queue with an idempotency primitive and a database-native fence.
What SheetForge actually does
Every write lands in Postgres first as a ledger entry, tagged with an idempotency key, indexed with a partial unique constraint so retries dedupe at the database level. A worker pulls from a Redis stream, one sheet at a time, wrapped in a Postgres advisory lock inside a transaction. The lock is a Postgres primitive — when the transaction commits or rolls back, the lock releases automatically. No TTL. No lease clock. A crash mid-handler rolls the transaction back, Redis redelivers the message, and the idempotency key catches the replay.
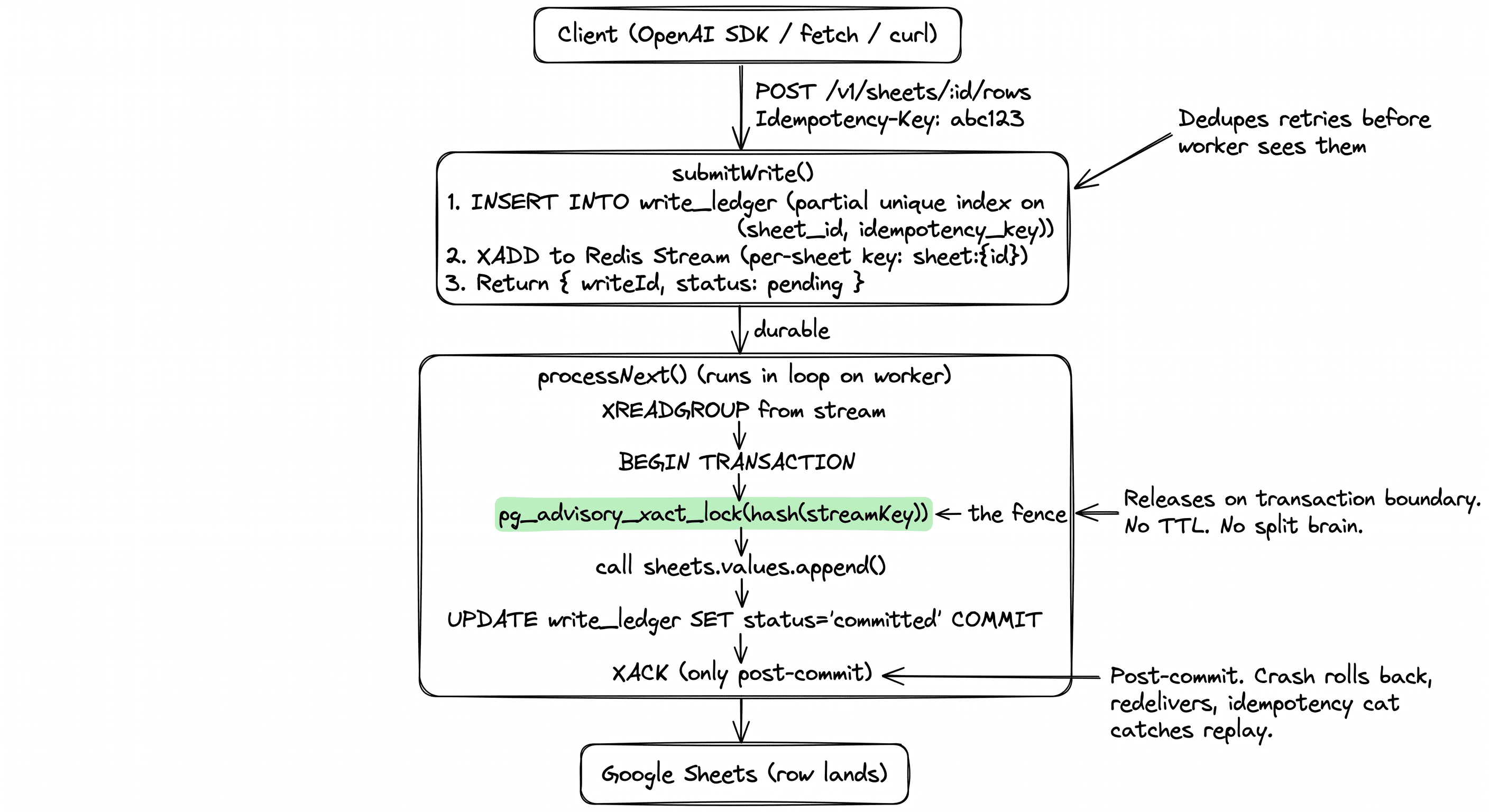
Four things matter here:
The advisory lock is the fence. pg_advisory_xact_lock releases on transaction boundaries. There is no split-brain condition. If your worker dies, Postgres releases the lock for you.
The idempotency key is the deduper. Every write includes Idempotency-Key. A partial unique index blocks duplicate payloads before the worker sees them. Retry 100 times, get 1 row.
The ledger is the truth. Your write is durable the moment the API returns a writeId. Sheets is downstream. If Google is rate-limiting or down, writes queue up and flush later.
XACK happens post-commit. Redis Streams' pending entries list redelivers unacked messages. Exactly-once semantics, for real.
Run the same 50-parallel-writes test against this: 50 rows, every time, in order. Retry safe. No drops.

The typed SDK was the bonus
Once the queue worked, users asked for one thing more than any other: stop the stringly-typed free-for-all.
Every column in Sheets is a string by default. Rename a column in the sheet, deploy, and find out at runtime that your form is writing to the wrong cell.
Since SheetForge reads your header row, it generates a typed TypeScript client. Your header row is the schema.
import { createClient } from './sheetforge-client'
const sheet = createClient({
apiKey: process.env.SHEETFORGE_API_KEY!,
sheetId: 'sht_abc123',
})
await sheet.rows.insert(
{
email: 'hi@example.com',
plan: 'free', // 'free' | 'pro' — inferred from sample cells
created_at: new Date().toISOString(),
},
{ idempotencyKey: crypto.randomUUID() },
)plan is typed as 'free' | 'pro' because those were the sample cell values. The compiler catches drift. Rename a column in the sheet and regenerate, TypeScript tells you every call site that needs updating.
This turned out to be the most-loved feature. The queue is invisible when it works — you just stop losing rows. The typed SDK is tactile.
How it compares

If you need webhooks today, use SheetDB. If you need your rows to land, come back.
Get it running
One-click hosted: getsheetforge.vercel.app
Sign in with Google. Connect a sheet. Copy the API key. Two minutes end-to-end.
Self-host:
git clone https://github.com/Devansh-365/sheetforge.git
cd sheetforge
pnpm install
cp .env.example .env
pnpm db:push
pnpm devNode 20+, pnpm 9+, Postgres 14+, Redis 6+ (or Upstash REST for Workers).
The OSS core — packages/queue, packages/codegen, packages/sdk-ts — is MIT and stays free forever. The managed SaaS runs the same code.
What SheetForge is not
It is not a Postgres replacement. If you need joins, transactions across multiple tables, indices, or complex queries, use a real database.
It is not a high-throughput pipe. Google caps writes at roughly 60/minute per sheet regardless of what's in front. SheetForge makes sure those 60 writes land. It doesn't raise the cap.
It is not a permanent backend for a growing product. It's the right tool when you need rows to land reliably on a surface your non-technical teammates can already edit. Landing pages, waitlists, internal forms, ops dashboards, MVPs. When you outgrow Sheets, you outgrow SheetForge.
The one take
Every Sheets-as-backend wrapper you've been using has a silent data-loss bug that only shows up when traffic spikes. That's exactly the moment you most care about losing rows.
Most of the indie web is running on this stack. Most of it has this bug. Most of the affected people won't ever know, because the drops are invisible.
If you've ever shipped a form on Sheets and watched rows vanish mid-launch, give SheetForge a try. If it saves you one bug, star the repo.
GitHub: github.com/Devansh-365/sheetforge
Hosted: getsheetforge.vercel.app
License: MIT.
You can also read about why I ditched LiteLLM after the supply chain attack or how I validated Metis before writing code.
Interested in working together?